Blog
Unsuccessful Git branching model
Tagi: branch, continous integration, feature flags, flow, git

Gdy po raz pierwszy w pracy natknąłem się na repozytorium GIT, poznałem też metodę prowadzenia struktury gałęzi zwaną “successfull git branching model”. Opiera się ona na kilku podstawowych zasadach:
- istnieje wersja stabilnej wersji kodu w głównej gałęzi “master”
- rozwój prowadzony jest na gałęzi deweloperskiej poprzez scalanie gałęzi featureowych “feature branch”
- cykle wydań produktu prowadzone są na gałęziach “release”
- poprawki wprowadzane są na gałęziach typu “hotfix”
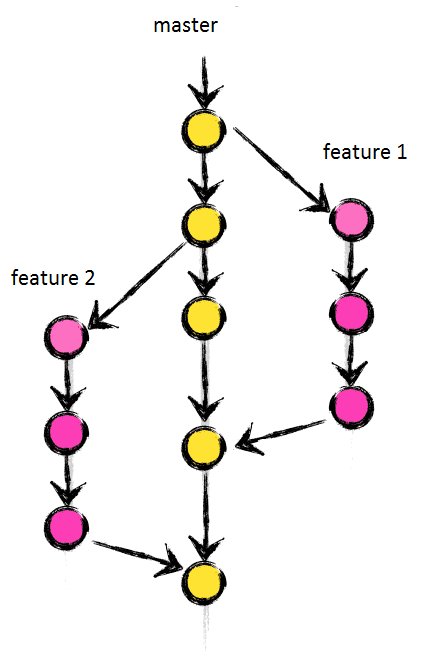
W idealnej sytuacji model taki przedstawia się jak na poniższym schemacie:

Przez długi okres wydawało mi się to jedynym sensownym i poukładanym rozwiązaniem. Wszelkie zmiany realizowane były w usystematyzowany sposób, wiadomym również było gdzie każda ze zmian musi trafić. Dodatkowo rozróżnienie na gałęzie wydań produktu pozwalało na dopasowanie do cyklu sprintowego który regulował faktyczny rytm pracy zespołu. Umożliwiało jednoczesne wprowadzanie poprawek, stabilizacji nowej wersji, oraz dalszy rozwój.
Problemy
Konflikty.
Jeśli spojrzymy na przedstawiony wykres to zaobserwować można że konflikt może nastąpić:
- między gałęzią główną a wydaniową,
- między gałęzią wydaniową a rozwojową,
- …i w każdym węźle grafu w którym schodzą się 2 niezależne ścieżki zmian.
Dodatkowym problemem jest fakt że konflikty występują głównie podczas scalania ze sobą gałęzi które kumulują zmiany
Kumulowanie zmian.
Gałęzie wydaniowe kumulują w sobie duże funkcjonalności oraz poprawki do nich, są one przemieszane ze sobą. Wycofanie funkcjonalności w przypadku gdy nastąpi taka decyzja może okazać się trudne w realizacji.
Mała przejrzystość historii.
Zamiast przejrzystego obrazu łączonych ze sobą zmian (jak na grafie powyżej), okazuje się że nasza historia zmian wygląda następująco: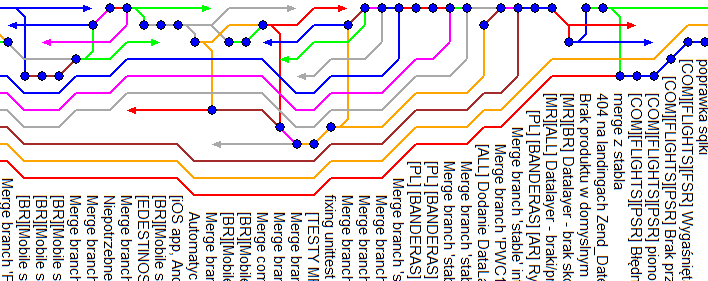
Oczywiście można wysnuć twierdzenie że w każdym przypadku gdy nad fragmentem dokumentu pracuje więcej niż jedna osoba może dojść do konfliktu. To prawda, z doświadczenia mogę stwierdzić nawet że jeśli obie te osoby pracują w jednym zespole to z reguły te konflikty udaje się sprawnie rozwiązać. Nie zawsze jest to jednak łatwe. Wyobraźmy sobie że z jednej strony możemy mieć efekt kilkutygodniowej pracy całego zespołu, z drugiej krytyczną poprawkę wpływającą na sprzedaż w naszym serwisie. Jeśli dodatkowo nad jednym produktem pracuje wiele zespołów, to scalanie zmian i rozwiązywanie konfliktów może spaść na osobę która może nie znać skonfliktowanych fragmentów kodu, ponieważ nie był on ich autorem. Jeśli założymy że każda zmiana jest w stanie wprowadzić regresję do działającej aplikacji, to każde scalenie kilku zmian potęguje problem, oraz utrudnia jego znalezienie. Pojawia się pytanie…
Jak uniknąć konfliktów ?
Powyższe pytanie defacto można przetłumaczyć, na pytanie: “Jak uniknąć łączenia ze sobą niezależnych ścieżek zmian”. Odpowiedzią na to pytanie jest uproszczenie modelu wprowadzanych zmian. Sprowadza się to do kilku nowych zasad:
- istnieje wersja stabilnej wersji kodu w głównej gałęzi “master”
- wszelkie zmiany scalamy bezpośrednio do głównej gałęzi,
niezależnie czy są to poprawki “hotfix”, czy nowe funkcjonalności “feature”. Defacto wszystko traktujemy jak feature.
Uproszczony model będzie wyglądał następująco:
Nie eliminujemy co prawda w ten sposób możliwości wystąpienia konfliktów, a jedynie minimalizujemy tą możliwość. Mogą wystąpić wyłącznie między gałęziami featureowymi i główną gałęzią kodu. Dodatkowo, odpowiedzialność za rozwiązanie konfliktu nastąpi w chwili scalania zmian więc osoba / zespół scalający zmianę ma do czynienia zawsze ze swoim kodem i powinien go rozumieć. Jeśli dodatkowo przed scaleniem gałęzi zaktualizujemy ją (operacja rebase) o najświeższy kod na głównej gałęzi (master), to możemy przetestować efekt naszych zmian jeszcze przed scaleniem. Historia zmian w projekcie również znacznie się upraszcza, zmiany widoczne są jedna za drugą, w takiej kolejności w jakiej były integrowane, możemy je również w prosty sposób wycofywać.
Wprowadzenie tego modelu wymaga jednak zachowania dużej dyscypliny w prowadzeniu głównej gałęzi kodu, oraz zastosowanie następujących technik.
Pokrycie kodu testami regresyjnymi.
Każdy proces scalania zmian wiąże się z możliwością wprowadzenia regresji. Aby zminimalizować to ryzyko aplikacja musi być jak najlepiej pokryta testami.
Sterowanie włączonymi funkcjonalnościami (feature flags).
Aby uniknąć kumulowania się procesów integracji w jednym momencie (np na koniec sprinta), powinniśmy integrować je tak często jak tylko to możliwe. Gdy zmiany są gotowe pod względem funkcjonalnym, oraz stabilne. Jeśli nasz “biznes” nie jest gotowy na wprowadzenie zmiany dla użytkowników należy wyłączyć funkcjonalność za pomocą feature flagi.
Ciągły proces integracji.
Wprowadzenie tego procesu jest wynikową powyższych punktów. Częste procesy integracji zawierające sprawdzenie aplikacji testami regresyjnymi stają się bardzo pracochłonne. Dlatego konieczna jest automatyzacja tego procesu, co w praktyce oznacza że mamy już do czynienia z procesem ciągłej integracji.
Podsumowanie
Wprowadzenie uproszczonego modelu zmian w repozytorium pozwala na ograniczenie problemów związanych ze scalaniem. Musimy jednak być gotowi na wprowadzenie tych zmian. Testy regresyjne oraz feature flagi stanowią nie tylko wymóg do wprowadzenia tych zmian. Testy i tak powinny stanowić podstawę każdej nowoczesnej aplikacji. Natomiast feature flagi dają możliwość sterowania funkcjonalnościami w dalszym cyklu życia produktu, nie tylko podczas wprowadzania funkcjonalności. Proces ciągłej integracji w zasadzie nie jest możliwy w innym modelu, gdyż dąży się w nim do wprowadzania zmian jak najczęściej, najlepiej nawet bez użycia feature branchy. Ale to temat na osobny artykuł.

