Blog
Komunikacja pomiędzy komponentami w Angularze 1.5 [“NG 1.5 z placu boju” 3/7]
Ten post to 3-cia część serii “Angular 1.5 z placu boju”, prezentującej architekturę opartej na komponentach, “gotowej na NG 2” aplikacji w Angularze 1.5, nad którą pracujemy.
Wprowadzona w Angularze 1.5 metoda
module.component()może wydawać się kosmetycznym dodatkiem, jednak podejście, które ta metoda promuje (a które wykorzystujemy “do oporu”) owocuje zupełnie innym typem architektury niż opisywana w większości “klasycznych” tutoriali do Angulara, mam więc nadzieję, że uda Ci się na bazie naszych doświadczeń paru rzeczy dowiedzieć.Spis Treści:
- Czy opłaca się startować z nową aplikacją w Angularze 1.5?
- Aplikacja w Angularze 1.5 jako drzewo komponentów
- Komunikacja pomiędzy komponentami w Angularze 1.5 [TEN POST]
- Elastyczna struktura projektu w Angularze 1.5 (architektura “fraktalna”) [WKRÓTCE]
- Pisanie projektu w Angularze 1.5 w ES6/ES2015 [WKRÓTCE]
- Testowanie jednostkowe komponentów Angulara 1.5 – szczegółowy przewodnik [WKRÓTCE]
- Testy E2E opartej na komponentach aplikacji w Angularze 1.5 [WKRÓTCE]
Komponenty muszą ze sobą współpracować, by umożliwić złożone zachowanie biznesowe
W poprzednim poście tej serii opisywałem “statyczną” część opartej na komponentach architektury Angulara 1.5: anatomię komponentu i to w jaki sposób aplikacja może być ustrukturyzowana jako drzewo komponentów. Wspomniałem także, że używamy wielu małych, sfokusowanych komponentów. Nie poruszyłem natomiast jeszcze tego, w jaki sposób wszystkie te komponenty się ze sobą komunikują (przekazują dane i propagują akcje użytkownika oraz zmiany stanu aplikacji). To właśnie będzie tematem tego posta.
Jednokierunkowy przepływ danych (z góry na dół)
Jednym z dobrych sposobów na uczynienie złożonego drzewa komponentów możliwym do ogarnięcia, spopularyzowanym przez React-a i zyskującym coraz większe poparcie wśród głównych frameworków JS, jest uczynienie komunikacji pomiędzy komponentami jednokierunkową i jawną, poprzez atrybuty komponentów.
jednokierunkowy przepływ danych ma kilka zalet:
- Wspiera reużywalność. Komponent-dziecko, który nie wie o swoim rodzicu (tzn. nie jest związany z wewnętrznym stanem rodzica poprzez współdzielony scope ani nie powoduje u swojego rodzica efektów ubocznych poprzez dwukierunkowe bindingi) może być w prosty sposób wyjęty z kontekstu swojego rodzica i przerzucony do innego rodzica.
- Łatwiej jest go analizować. Dotyczy to zarówno pojedynczych komponentów (jeżeli komponenty nie są ze sobą powiązane, mogą być analizowane niezależnie) jak i całego drzewa komponentów (gdy nie występują w nim pętle ani efekty uboczne, znacznie łatwiej jest śledzić przepływ).
- Ułatwia testowanie komponentów. Komponenty nie powiązane ze swoim rodzicem ani swoimi dziećmi (poprzez niejawne parametry wejściowe lub wyjściowe) stają się bardziej “funkcyjne”, łatwiejsze do odizolowania.
jednokierunkowy przepływ danych w NG 1.5
Komponenty Angulara 1.5 doskonale pasują do jednokierunkowego przepływu danych.
Scope komponentów NG 1.5 jest domyślnie wyizolowany, co wymusza przekazywanie danych w jawny sposób, poprzez atrybuty komponentów. Eliminuje to pierwszą główną przyczynę powiązań pomiędzy komponentami. Drugą główną przyczynę powiązań – dwukierunkowe bindingi – można wyeliminować używając kolejnej nowości NG 1.5: bindingów jednokierunkowych ('<').
zobaczmy, jak jednokierunkowy przepływ danych NG 1.5 wygląda w kodzie:
(wszystkie fragmenty kodu są w składni ES6/ES2015 – więcej na ten temat w jednym z kolejnych postów)
angular.module('TodoApp', []).component('todosController', {
controller: class {
constructor(todoService) {
todoService.loadTodos().then((todos) => {
this.todos = todos;
});
}
get showProgress() {
return angular.isUndefined(this.todos);
}
get showList() {
return angular.isDefined(this.todos);
}
},
template: `
Przykład jest oczywiście uproszczony, tak by uwidocznić jedynie główne zasady jednokierunkowego przepływu danych. Komponenty byłyby normalnie nieco bardziej złożone. Na przykład todosController mógłby wyświetlać także menu górne i sidebar, ilość wykonanych todos-ów mogłaby być cache-owana albo pobierana z serwera itd. – ogólny “styl” przepływu informacji byłby jednak identyczny.
kilka istotnych spostrzeżeń nt. powyższego kodu:
- Komponenty niższego poziomu są tak “bezmyślne”, jak to tylko możliwe. Zwróć np. uwagę, jak komponent
<todo-summary>(wykorzystywany w szablonie komponentutodoList) przyjmuje wszystkie wyświetlane przez siebie liczniki jako parametry. Nie ma on pojęcia w jaki sposób je pobrać albo wyliczyć, wie jedynie jak je zaprezentować w postaci schludnego podsumowania. - Wszystkie bindingi są jednokierunkowe. Poza bindingami łączącymi pola formularza z polami kontrolera w obrębie pojedynczego komponentu, w opartej na komponentach architekturze NG 1.5 nigdzie indziej nie występuje potrzeba wykorzystania dwukierunkowych bindingów.
- Komponenty na wszystkich poziomach hierarchii wykorzystują dużą ilość metod pomocniczych. Zwórć dla przykładu uwagę na metody
showProgressishowListw klasietodosController(oraz na fakt, że mamy dwie jawne, przeciwstawne metody zamiast po prostu jedną z nich użyć w szablonie z negacją). Zauważ także w jaki sposób korzystamy z metodtextorazisCompletedw komponencietodoItem, mimo że zysk wydawać by się mógł minimalny (skrócenie wywołania w szablonie zaledwie o jedną kropkę:$ctrl.isCompletedzamiast$ctrl.item.isCompleted). Takie masowe wykorzystanie metod pomocniczych nie jest wprawdzie nieodłączną cechą jednokierunkowego przepływu danch, jednakże doskonale go wspomaga dzięki temu, że przepływ danych staje się łatwiejszy do zaobserwowania i łatwiej za nim podążać poprzez drzewo komponentów.
Komponenty Kontrolery i Komponenty Prezentacyjne
Kolejną rzeczą, którą mogłeś zauważyć w powyższej próbce kodu, jest to, że dane są ładowane z serwera jedynie w komponencie najwyższego poziomu (todosController). Wszystkie pozostałe komponenty niższego poziomu wyświetlają jedynie dane przekazane im poprzez atrybuty tagów, nigdy jednak nie komunikują się bezpośrednio ze światem zewnętrznym.
Typowa aplikacja będzie zawierać jedynie kilka komponentów, zazwyczaj wysokopoziomowych, komunikujących się ze światem zewnętrznym (nazywamy je Komponentami Kontrolerami) oraz wiele niskopoziomowych komponentów odpowiedzialnych za wyświetlanie danych przekazywanych im w dół z Kontrolerów (nazywamy je Komponentami Prezentacyjnymi).
Taki podział odpowiedzialności zapewnia, że logika biznesowa i prezentacyjna nigdy się ze sobą nie przeplatają, przez co aplikacja staje się łatwiejsza do zrozumienia.
Powyższe dwa typy komponentów charakteryzują się następującymi cechami:
Komponenty Kontrolery:
- zawierają logikę biznesową aplikacji
- komunikują się z serwerem
- mają bardzo proste szablony (nie zawierają złożonego HTML-a, jedynie wyświetlają bądź ukrywają swoje komponenty-dzieci)
- są stanowe, bardziej przypominają klasy
Komponenty Prezentacyjne
- zawierają jedynie logikę i stan związane z prezentacją (a wiele z nich jest w ogóle bezstanowych)
- nie komunikują się z serwerem
- mogą mieć złożone szablony, o skomplikowanej strukturze HTML (choć nie muszą – wiele prezentacyjnych komponentów jest małych i prostych)
- są bardziej funkcyjne
wraz ze wzrostem aplikacji mogą być wprowadzane dodatkowe Komponenty Kontrolery
W powyższym przykładzie, komponent todoSummary jest prostym prezentacyjnym komponentem przyjmującym dwa patametry: ilość wszystkich todo-sów i ilość wykonanych todo-sów.
angular.module('TodoApp', []).component('todoList', {
// ...
template: `
...
Jednakże, gdybyśmy w przyszłości chcieli prezentować bardziej złożone podsumowanie (np. rozszerzone o dane historyczne, statystyki produktywności użytkownika itp.) komponent todosController musiałby ładować i przekazywać w dół wielką ilość (w większości nie powiązanych ze sobą) informacji, i strasznie by przez to spuchł.
By temu zapobiec, moglibyśmy wprowadzić dodatkowy Komponent Kontroler, odpowiedzialny za ładowanie danych do podsumowania:
angular.module('TodoApp', []).component('todoList', {
// ...
template: `
...
Zwróć uwagę, że nie dodaliśmy logiki związanej z ładowaniem statystyk bezpośrednio do komponentu todoSummary, ale wprowadziliśmy dodatkowy komponent todoSummaryController, przez co oba obszary odpowiedzialności (ładowanie i formatowanie danych) nadal są rozdzielone. Pozostawiliśmy także oryginalny komponent todoSummary (dodaliśmy jedynie do niego więcej atrybutów), ale oczywiście moglibyśmy go rozdzielić na kilka mniejszych, bardziej sfokusowanych komponentów, jeśli ilość wyświetlanych statystyk wzrośnie – dzięki naszemu nowemu komponentowi todoSummaryController będzie to łatwe.
Wprowadzanie nowych Komponentów Kontrolerów wraz ze wzrostem aplikacji jest typowym scenariuszem. Niektóre z Twoich początkowych, wysokopoziomowych Komponentów Kontrolerów mogą nawet na pewnym etapie zdegradować się do Komponentów Prezentacyjnych, definiujących jedynie layout dla grupy nowych, bardziej sfokusowanych Komponentów Kontrolerów.
Przekazywanie akcji użytkownika w górę
Przepływ danych to tylko jedna strona medalu. Druga strona to przetwarzanie i propagowanie akcji użytkownika w górę drzewa komponentów, of niskopoziomowych elementów interfejsu (przycisków, linków, pól formularzy itd.) do wysokopoziomowych Komponentów Kontrolerów, zarządzających logiką biznesową.
Komponenty Kontrolery i Komponenty Prezentacyjne w kontekście przesyłania akcji w górę
W pierwszej części artykułu omówiłem dwa typy komponentów: Komponenty Kontrolery, odpowiedzialne za logikę biznesową aplikacji, i Komponenty Prezentacyjne, odpowiedzialne za interfejs aplikacji.
Podział odpowiedzialności pomiędzy tymi komponentami pozostaje dokładnie taki sam także w kontekście obsługiwania akcji użytkownika:
- Komponenty Prezentacyjne zajmują się niskopoziomowymi, technicznymi detalami odczytywania działań użytkownika (klikania w przyciski, wypełniania pól formularzy itp.) oraz mapowaniem ich na bardziej “semantyczne” akcje (“utwórz nowe todo“, “wyświetl kolejną stronę wyników” itd.). Informują one swoje nadrzędne Komponenty Kontrolery o tych semantycznych akcjach, nie wykonują jednak samodzielnie żadnej powiązanej z tymi akcjami logiki biznesowej ani nie komunikują się z serwerem – ich odpowiedzialność kończy się na etapie zarejestrowania akcji i przesłania jej w górę w celu dalszego przetwarzania.
- Komponenty Kontrolery przetwarzają semantyczne akcje otrzymane od swoich podrzędnych Komponentów Prezentacyjnych. Wykonują one stosowną logikę biznesową, przesyłają wyniki akcji do serwera i propagują wywołane akcją zmiany stanu aplikacji spowrotem w dół drzewa komponentów. Nigdy jednak bezpośrednio nie wyłapują niskopoziomowych akcji użytkownika ani nie zajmują się ich technicznymi szczegółami.
dwa typy Komponentów Prezentacyjnych
Jak wspomniałem przed chwilą, mamy 2 typy akcji: niskopoziomowe, “atomowe” akcje i wysokopoziomowe, “semantyczne” (on-click vs on-add-todo). W analogiczny sposób możemy wyróżnić dwa typy Komponentów Prezentacyjnych:
- Komponenty Atomowe. Są to zazwyczaj niskopoziomowe komponenty: przyciski, checkboxy itp. Przekazują one w górę niskopoziomowe, techniczne akcje takie jak
onClickczyonKeypress. Mogą istnieć także bardziej złożone Komponenty Atomowe, takie jak np. widget z kalendarzykiem, przekazujące w górę bardziej złożone akcje, np.onSelectDate, jednak nadal są to akcje techniczne, nie osadzone w terminologii domeny biznesowej aplikacji. Komponenty Atomowe są uniwersalne, przenaszalne pomiędzy różnymi aplikacjami. - Komponenty Semantyczne. Są to komponenty wysokopoziomowe, ściśle powiązane z domeną biznesową aplikacji, np.
todoItemalbocontactsList. Komponenty Semantyczne korzystają wewnętrznie z Komponentów Atomowych, przemapowują jednak akcje pochodzące z Komponentów Atomowych na bardziej abstrakcyjne, wyrażone w nomenklaturze domeny biznesowej aplikacji, np.onCompleteTodoalboonAddNewContact. Tego typu komponenty nie są przenaszalne pomiędzy różnymi aplikacjami.
Istnieją dwa ważne wzorce powiązane z takim właśnie podziałem Komponentów Prezentacyjnych:
- Komponenty Kontrolery powinny zawsze otrzymywać wyłącznie semantyczne akcje. Atomowe, techniczne akcje nigdy nie powinny docierać do Komponentów Kontrolerów. Powinny zawsze być przemapowane na domenową terminologię biznesową zanim dotrą do Kontrolera.
- Komponenty Atomowe powinny wiedzieć jak najmniej na temat kontekstu, w którym są wykorzystywane. Przycisk ‘Oznacz Todo Jako Ukończone’ powinien wiedzieć jedynie, że w niego kliknięto, i powinien przekazać tą informację wyżej, do bardziej semantycznego komponentu, który potrafi to kliknięcie odpowiednio zinterpretować (np. do komponentu
todoItemalbotodoList). Przycisk nie powinien nigdy znać ID todo-sa, który ma zostać oznaczony jako wykonany, ani nawet rozumieć, że kliknięcie oznacza cokolwiek powiązanego z todo-sami. Ta informacja powinna zostać dodana przez jego rodzica podczas przemapowywania atomowej akcji na semantyczną.
3 sposoby przekazywania akcji w górę
W naszej aplikacji wykorzystujemy do przekazywania akcji w górę trzy mechanizmy:
callbacki (bindingi ‘&’)
Komunikacja poprzez callbacki to “oficjalny” i najprostszy sposób przekazywania informacji do komponentu-rodzica. Komponent-dziecko może wywołać callback dostarczony przez swojego rodzica w taki sposób:
angular.module('TodoApp', []).component('todosController', {
controller: class {
// ...
addTodo(title, description) {
// ...
}
},
template: `
...
Zwróć uwagę na nieco nietypowy sposób przekazywania parametrów z komponentu-dziecka (onAddTodo({ title: $ctrl.title, description: $ctrl.description }) zamiast po prostu onAddTodo($ctrl.title, $ctrl.description)). Powodem jest to, że binding '&' nie jest tak na prawdę funkcją-callbackiem, ale wyrażeniem, a title i description nie są parametrami funkcji, ale zmiennymi widocznymi w sope kontekstu wyrażenia. W komponencie-rodzicu moglibyśmy równie dobrze zrobić coś takiego: on-add-todo="$ctrl.todoText = title + ' ' + description", chociaż nie polecamy tego i nigdy czegoś takiego w naszej aplikacji nie robimy.
Zalety: Jawne API. W opcji bindings widać bezpośrednio, jakie callbacki komponent-dziecko udostępnia. Łatwo jest także zobaczyć w szablonie kompnentu-rodzica, których spośród udostępnionych callbacków rodzic używa i w jaki sposób. Czyni to komunikację pomiędzy komponentami w pełni jawną i łatwą do zrozumienia.
Wady: Komunikacja jest możliwa jedynie z bezpośrednim rodzicem. Nie jest możliwe przeskoczenie przez więcej niż jedną warstwę komponentów, tak więc jeśli istnieje więcej warstw pomiędzy komponentem, będącym źródłem akcji, a komponentem, który powinien tą akcję obsłużyć, będziesz musiał “przepychać” akcję przez wszystkie warstwy pośrednie, co szybko staje się uciążliwe i sprawia, że drzewo komponentów trudniej się refaktoryzuje.
Kiedy używać: callback '&' powinien być domyślnie używany we wszystkich Komponentach Atomowych. Są one przewidziane do tego, by być re-używane, co jawne API ułatwia. Dodatkowo, akcje z Komponentów Atomowych i tak powinny być przemapowane na bardziej semantyczne przez ich bezpośredniego rodzica, tak więc w przypadku Komponentów Atomowych problem przepychania akcji przez wiele warstw pośrednich nie występuje.
lokalne eventy $scope
Kolejnym wbudowanym mechanizmem Angulara, pozwalającym na przesyłanie akcji w górę, są lokalne eventy $scope. Komponent-dziecko może za ich pomocą przekazać akcję w górę w taki sposób:
angular.module('TodoApp', []).component('todosController', {
controller: class {
constructor($scope) {
$scope.$on('ADD_TODO', (event, title, description) => {
// ...
});
}
// ...
},
template: `
...
Zalety: Bardziej elastyczna struktura drzewa komponentów, łatwiejsza do refaktoryzacji. Eventy mogą transparentnie przenikać przez pośrednie warstwy komponentów, co sprawia że przenoszenie komponentu w górę lub dół hierarchii albo wstawianie dodatkowych komponentów pomiędzy źródło i konsumenta danej akcji staje się banalnie proste – nie musisz jawnie łapać i ponownie emitować akcji w każdym pośrednim komponencie.
Wady: Niejawne API. Nie da się tak łatwo, jak w przypadku bindingów '&' zobaczyć, jakie eventy dany komponent emituje. Jest również trudniej wyśledzić, który komponent łapie wyemitowany event, ponieważ nie musi to być bezpośredni rodzic komponentu emitującego, ani nie jest to widoczne nigdzie w szablonie. Kolejną wadą jest to, że eventy $scope mogą podróżować jedynie w górę, mogą być więc obsłużone jedynie przez komponenty znajdujące się powyżej w drzewie komponentów, ale nie poprzez komponenty-rodzeństwo ani komponenty w innych częściach interfejsu.
Kiedy używać: Przekazywanie akcji przy pomocy eventów $scope idealnie pasuje do Komponentów Semantycznych. Są one często oddzielone od swoich Komponentów Kontrolerów kilkoma warstwami prostych komponentów layoutowych. Eventy umożliwiają tunelowanie akcji poprzez wszystkie te komponenty pośrednie. W przypadku Komponentów Atomowych ma to mniej sensu, ponieważ generowane przez nie akcje i tak są przeważnie łapane i przemapowywane na bardziej semantyczne przez ich bezpośredniego rodzica.
globalne eventy $rootScope
Ostatni mechanizm Angulara, jakiego używamy do przekazywania informacji o zmianach stanu aplikacji, to globalne eventy $rootScope.
Składnia jest identyczna jak w przypadku eventów $scope, nie będę więc powielał kodu – spójrz na sekcję powyżej i po prostu zastąp wszystkie wystąpienia frazy $scope frazą $rootScope. Istnieje jednak jedna istotna różnica w działaniu eventów $rootScope: nie bąbelkują one w górę drzewa komponentów, ale subskrybuje się do nich globalnie, na najwyższym poziomie, poprzez $rootScope.
Zalety: Można w ten sposób połączyć ze sobą dwa dowolne komponenty, niezależnie w jakim miejscu hierarchii drzewa komponentów się znajdują. Umożliwia to przekazywanie informacji pomiędzy komponentami-rodzeństwem, a nawet pomiędzy dwoma zupełnie niezależnymi obszarami interfejsu. Możliwe staje się także przekazywanie eventów pomiędzy komponentami i servisami.
Wady: Globalne eventy są… globalne, i jak wszystko co globalne powinny być używane z rozwagą. W przeciwnym przypadku Twoja aplikacja może szybko stać się trudna do zrozumienia i utrzymania. Przy globalnych eventach jeszcze mocniej zarysowuje się główna wada eventów lokalnych: niejawne API. W przypadku globalnych eventów jeszcze trudniej jest jest znaleźć, kto obsługuje dany event, ponieważ odbiorca nie musi znajdować się bezpośrednio powyżej w drzewie komponentów; event może być potencjalnie przechwycony przez jakikolwiek komponent w obrębie całej aplikacji, a nawet w ogóle nie przez kompoentn, ale przez serwis.
Kiedy używać: Do synchronizacji pomiędzy wysokopoziomowymi Komponentami Kontrolerami, zarządzającymi różnymi obszarami interfejsu. Aplikacja składa się zazwyczaj z kilku luźno powiązanych części (np. aplikacja typu “ToDo” może wyświetlać listę todo-sów w głównym panelu, a w sidebarze listę kategorii albo tagów). Odpowiedzialności obu tych części są wystarczająco niezależne, by uzasadnione było użycie osobnych Komponentów Kontrolerów i osobnych pod-hierarchii drzewa komponentów. Jednakże, mimo że w przeważającej części rozdzielne, nie są one kompletnie niezależne – np. skasowanie todo-sa w głównym panelu powinno odświeżyć liczniki ilości todo-sów dla kategorii w sidebarze. Globalne eventy $rootScope są doskonałym narzędziem do takiej synchronizacji.
przepływ akcji przez drzewo komponentów – kompletny przykład
Poniżej możesz zobaczyć, w jaki sposób wszystkie trzy sposoby przekazywania akcji mogą koegzystować w jednej aplikacji:
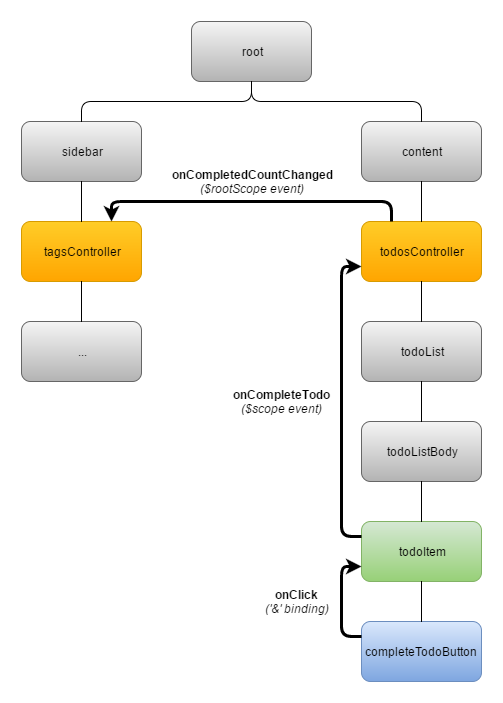
Przycisk (Komponent Atomowy) generuje niskopoziomową, techniczną akcję: onClick. Ponieważ akcja ta jest natychmiast wyłapywana przez bezpośredniego rodzica przycisku, komponent todoItem, jest ona przekazywana poprzez binding '&'. Komponent todoItem (Komponent Semantyczny) przemapowuje techniczną akcję w akcję semantyczną, używającą nomentklarury domeny biznesowej aplikacji: onCompleteTodo. Akcja ta jest następnie tunelowana poprzez kilka pośrednich warstw komponentów czysto layoutowych, przy pomocą mechanizmu eventów $scope. Komponent todosController (Komponent Kontroler) obsługuje akcję (wysyła request do serwera, przerenderowuje fragment drzewa komponentów za który jest odpowiedzialny itd.). Dodatkowo, informuje on inny Komponent Kontroler, zarządzający listą tagów w sidebarze, że zmieniła się ilość zakończonych todo-sów (by sidebar mógł zostać odświeżony, jeśli istnieje taka potrzeba). Ta komunikacja pomiędzy dwoma Komponentami Kontrolerami odbywa się poprzez event $rootScope.
Istotna uwaga: Z powyższego diagramu mogłoby się wydawać, że komponenty z niższego poziomu drzewa komponentów wysyłają akcje do komponentów położonych powyżej. Jednakże, ważne jest by zrozumieć, że nadawcy akcji są tak na prawdę całkowicie nieświadomi ich odbiorców. Przycisk completeTodoButton wywołuje po prostu callback przekazany mu poprzez binding, nie wie jednak kto mu ten callback przekazał ani jak zostanie on zinterpretowany. Podobnie, komponent todoItem emituje event $scope, nie wie jednak który komponent, ani ile warstw powyżej, przechwyci i obsłuży ten event. Nawet komponent todosController nie wysyła eventu onCompletedCountChanged bezpośrednio do komponentu tagsController; emituje on jedynie ten event poprzez $rootScope, nie wie jednak czy i jak wiele innych Komponentów Kontrolerów albo serwisów zasubskrybuje się jako odbiorcy tego eventu.
a co z Flux-em?
Nasza architektura jest koncepcyjnie bardzo zbliżona do spopularyzowanej przez React-a architektury Flux. Czemu więc nie zaadaptowaliśmy po prosu jednej z dostępnych Flux-owych bibliotek?
Odpowiedzi należy szukać w naszej filozofii stopniowej progresji. Świadomie zdecydowaliśmy się zacząć od najprostszych możliwych narzędzi, idealnie jedynie tych wbudowanych w Angulara. Dlatego właśnie rozpoczęliśmy od jqLite, ngRoute i “gołego” $http zamiast od pełnego jQuery, UI Router-a czy Restangular-a. Była to dobra decyzja: znacznie spłaszczyła naszą krzywą nauki, a po 4 miesiącach developmentu te narzędzia wciąż zaspokajają nasze potrzeby.
W podobnie minimalistyczny sposób podeszliśmy do architektury naszego drzewa komponentów. W tym przypadku jednak początkowe, proste rozwiązanie okazało się niewystarczające. Nie był to jednak wielki przeskok, ale stopniowa progresja:
- Z początku nasze drzewo komponentów było relatywnie płytkie, korzystaliśmy więc jedynie z bindingów
'&'. Przechowywaliśmy również całość stanu naszej aplikacji wewnątrz komponentów. - Gdy aplikacja zaczęła rosnąć a drzewo komponentów stawać się głębsze, wprowadziliśmy lokalne eventy
$scope. Nadal jednak mieliśmy tylko 2 Komponenty Kontrolery. - Gdy aplikacja urosła jeszcze bardziej, wprowadziliśmy więcej Komponentów Kontrolerów oraz globalne eventy
$rootScope, by mogły się one ze sobą synchronizować. Stan naszej aplikacji nadal jednak przechowywaliśmy w całości wewnątrz komponentów. - Naszym najświeższym krokiem było rozpoczęcie przenoszenia fragmentów stanu aplikacji z komponentów do scentralizowanego, Flux-o podobnego “Data Store” (zaimplementowanego jako Angularowy serwis).
Wciąż nie czujemy potrzeby wprowadzania zewnętrznej Flux-owej biblioteki. Angular dostarcza wystarczających narzędzi by zapewnić solidną architekturę aplikacji bez konieczności uciekania się do zewnętrznych bibliotek. Jednakże, nasza aplikacja nadal rośnie, nie wykluczamy więc myśli, że moglibyśmy na pewnym etapie taką bibliotekę wprowadzić.
Wnioski
Przedstawiona w tym poście architektura przepływu danych i akcji sprawdza się w naszym przypadku naprawdę dobrze. Rozwijaliśmy ją i testowali w ogniu walki stopniowo, przez 4 miesiące prac nad naszą aplikacją, i jesteśmy zadowoleni z rezultatów. Namawiamy Cię bardzo mocno do wypróbowania podobnego podejścia w Twojej aplikacji. Koncepcyjnie podobną architekturę można osiągnąć na wiele sposobów, przy użyciu różnorakich narzędzi, chcielibyśmy Cię jednak zachęcić, byś w pierwszej kolejności spróbował funkcjonalności wbudowanych w Angulara, zanim sięgniesz po zewnętrzne biblioteki.
Co Ty o tym sądzisz?
W jaki sposób przekazujesz akcje w swojej aplikacji? Czy masz jakiś ulubiony mechanim, czy używasz mieszaniny kilku różnych, podobnie jak my? Miałeś może okazję wypróbować w Angularze pełną Flux-ową architekturę? Podziel się z nami swoimi doświadczeniami w komentarzach poniżej!

